在我们日常的生活中,可用性是衡量一个东西好坏的标准。举个例子,一辆车,动力很足,内饰奢华,空间够大,安全性好,但是每半个小时就会熄火一次,这是个好车么?同样的道理,你设计一个APP,操作流畅,但是每半个小时就会Crash一次,显然也不是什么好APP。对于程序员来说,特别是对于后端开发来说,系统的可用性非常地重要,那么怎么衡量一个系统的可用性呢?

我们有两个重要的标准,一个是故障间隔时间,顾名思义,就是两次故障之间,相隔了多长的时间,很明显,故障间隔时间越长,说明系统越稳定。另一个是故障恢复时间,人非圣贤,孰能无过。故障总是会发生的,那么从故障开始,到发现问题,解决问题的时间,我们称之为故障解决时间,很明显,故障解决时间越短,说明解决问题的速度越快,系统越稳定。
我们把故障间隔时间/(故障间隔时间+故障恢复时间)称之为系统的可用率,很显然,这是个小于等于100%的数。我们把系统可用率99%以上的称之为2个9,把系统可用率99.9%以上的称之为3个9,很显然,越接近1,说明可用性越高。但是每当我们把可用性提高1个9,有多难么?
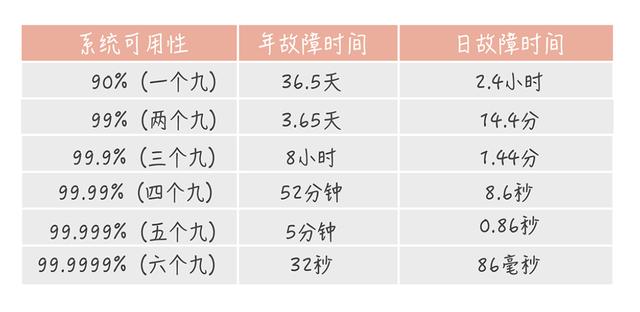
当系统的可用性为2个9的时候,我们的系统有3.65天是故障不可用的,这个看起来难度并不是很大,但是当我们把标准提高到4个9的时候,我们一年只有52分钟的时间允许故障,这是非常困难的,因为从故障的发生,到收到反馈,到定位,再修复,往往需要不少的时间。对于一个大公司来说,特别是一个有着千万甚至上亿月活的项目来说,故障的时间越长,影响的用户越多,那么就会造成越大的损失。
那么,为了提高系统的可用性,我们有哪些简单又行之有效的方法呢?
首先是规范好流程,代码的开发到发布上线,需要进行技术评审、代码审查、测试验证,不能够那么的随意,把线上环境当成测试环境使用。
其次是做好监控,自己发现用户而不是等用户发现问题,很多程序员,对处理异常、错误码非常地不屑,这是个非常不好的习惯,一般来说,好的代码,几乎60%都是用来处理异常跟边界情况地,如果不去做好这些,就很难从监控中去发现异常。
然后是,自动化的运维,人总是会犯错误的,并且还常犯,相信每个运维都重启错应用,或者部署错机器。而且人不可能24小时都盯着机器看,所以,我们需要自动化的运维,在某些机器故障的时候,快速进行响应。
最后则是定时的演练,在阿里巴巴,每年双十一前的3个月,都是进行压测跟演练,从而形成一套说明书,某某系统压力过高,降级停用了,其他系统该如何表现,让技术人员又心理准备,才能在故障真正发生地时候临危不乱。


科技有限公司")
科技有限公司")
 云存储架构的技术特点与三个发展方向
云存储架构的技术特点与三个发展方向
 关于边缘计算,企业需要知道的四件事
关于边缘计算,企业需要知道的四件事
 云迁移的实际成本
云迁移的实际成本
 五种不同类型的边缘解决方案
五种不同类型的边缘解决方案
 Kubernetes 架构指南
Kubernetes 架构指南
