
在业内前端构建,?般分为三种:
不过掌?教育在 2019 年之前,前端研发更多是在本地进?构建,再通过运维的脚本来进?部署,也容易 导致出现?产故障。所以我们收集反馈,结合实际情况,开发出 v1.0 构建模式,也取得了很好的成果。但 并没有以此就认为?枕?忧,也对很多痛点进?持续的优化,最后迭代出 v2.0 的?案。在这个过程中,前 端业务壮?,CI 构建经过 400+ 多应?,每周 2000+ 次构建,300+ 次的?产发布的?考,持续的成 ?。

v1.0 前端构建状况,?种是通过 webhook 来触发流?线构建,第?种是通过在 cd 上新建构建单来触构 建。如果构建任务?较多,按照单台机器的是远远不够,在这种情况下就需要借助 Jenkins 的 Master/Slave 的主从模式,来解决服务器的资源压?。让 Master 的服务器来进?调度资源,指定空闲 Slave 机器进?构建。当 Slave 机器上构建任务满了,构建任务继续在 Master 排队池中继续等待,等 Slave 空闲后,再进?分配。
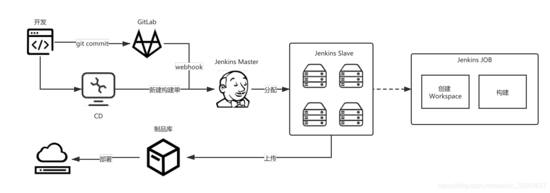
v1.0 不是最好的?案,同时暴露出第?次构建慢、错误?志反馈不明确等问题,另外?点就是 job 维护困 难。要解决这些问题,就需要重新开始,重新设计。
?先就是 JOB 维护困难,v1.0 的任务模式是多个应?对应 1 个 job,这就导致?个问题,如果 job 发版 导致挂了,影响到全部。假如需要复?该 job,进?定制化开发也?较困难。
其次第?次构建慢的问题,更多在资源调度上和?法复? Workspace,根据之前的资源调度模式,当我们 把任务分配到 A 机器,该任务被执?成功,那么下次的任务也会??到这台 A 机器。以此观察,就会发 现?部分任务都会优先去抢占 A 机器。这家就导致了?个问题:
最后是?法复? Workspace 模式,在 v1.0 情况下,不复? Workspace 模式是会带来以下优势:保证 node_module ?污染问题,同时也避免了 npm run build 的各种因为 node_module 包污染的问题,导 致的意外错误。所以在 v2.0 就需要应对污染的问题。同时也要考虑在复? Workspace 后,如何最?化 的利?其特点,?如,从 node_module 缓存、npm install 跳过等。
资源调度
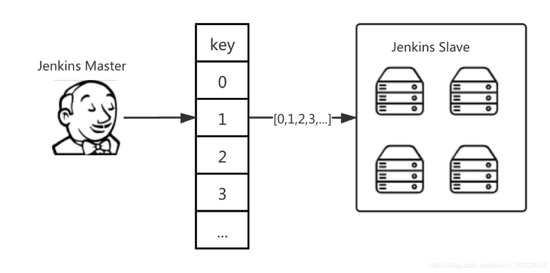
?先需要对资源调度进?优化,那就需要重新设计,把?组机器分为多个切?组,每个切?组调度顺序不 同。当应?触发构建时,分配对应的 key值:
- 1 AppNodeKey = AppId%nodes
再根据划分的 key,寻找对应的机器组,如 [0,1,2,3,4],构建任务去寻找 0 号机,寻找对应的 AppId 的 Workspace ?录地址去执?构建任务,假如任务被占?(默认是 2 个任务,这样可以优化资源不会被? 量任务抢占),会再寻找下?台机器,这样机器资源调度就会均衡化。
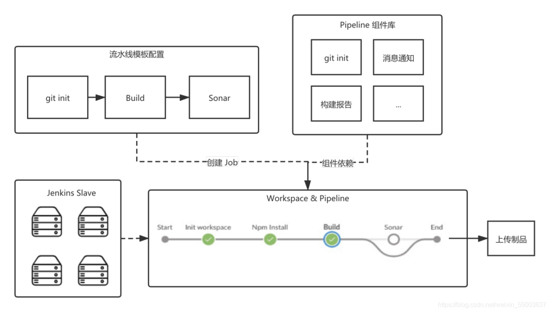
我们对不同的?程项?进?了模板化,?如 PC项?、H5 项?、游戏项?、hybrid 项?等等,在模板基 础上,我们?封装出来打包流?线模板,这样的好处是,我们可以??去针对各个类型的?程模板做?些 定向的配置优化,?如说我们的游戏类型项?,我们去做?个构建、打包,我们就可以在对应的开发组件 库依赖这?块,做?些对应的缓存、通知、报告等等。
流?线同时也带来了?些好处:
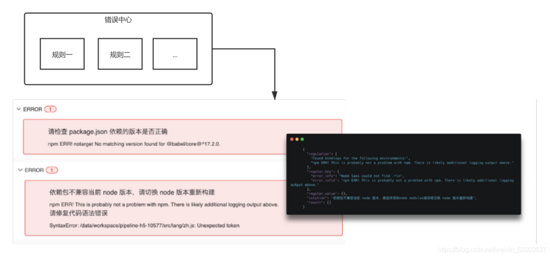
错误治理
不管是在本地还是 cd 平台上进?构建,也容易出现各种意想不到的错误。?如开发的疏忽,流?线的 git commit 未经过验证进?提交代码,都可能在 npm run build、或者 npm install 这两个阶段报出不同的 错误,所以就需要对?志提示进?分级集,划分为两种类型:
我们对 npm install、npm run build,及构建的各个阶段的观察,可以把失败归纳为 4 个触发 warning 或 error 类型:
遵守“观察?志-沉淀规则-修正反馈准确率”规则,来沉淀?志规则。
npm install 跳过
在复? Workspace 的情况下,已经 install 好的 node_modules,就没必要进??次重复 npm install, 就需要考虑只有依赖进?变更时,再重新 npm isntall。同时也容易带来问题,node_modules 污染,我 们采取了多种?式来避免 node_modules 被污染掉。
?前,我们对?以前的 v1.0 ?案,整体有了 20%+ 构建速度的提升,这对我们团队来说,也算是?个不 ?的正向激励,说明我们之前努?的?向是正确的。
在 v1.0 迁移到 v2.0,需要考虑如何进?平滑迁移,我们基于以下来进?迁移:
1:每个应?建?独? v2.0 Job 任务,?便快速变更及排查问题;
2:??上?持快速回滚到 v1.0;
3:选择 git commit、node 版本等信息保持不变,?感;
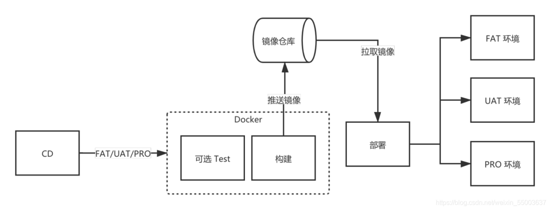
好的架构不是设计出来?是演进出来。在未来,构建任务可能会越来越多,项?也越来越复杂化,我们就 会考虑容器化?案,根据实际情况去考虑,容器构建,镜像发布,尽可能的节约资源。


科技有限公司")
科技有限公司")
 社交媒体分析在未来业务中将发挥着至关重要的作用
社交媒体分析在未来业务中将发挥着至关重要的作用
 腾讯云发布国内首款Serverless数据库 开启全栈Serverless时代
腾讯云发布国内首款Serverless数据库 开启全栈Serverless时代
 边缘计算云原生开源方案选型比较
边缘计算云原生开源方案选型比较
 探索增强IT基础设施保护的十种网络安全措施
探索增强IT基础设施保护的十种网络安全措施
 转向边缘计算? 考虑一下
转向边缘计算? 考虑一下
